Large Language Models (LLMs) are a cornerstone of modern artificial intelligence, powering applications like chatbots, text generation, and language translation.
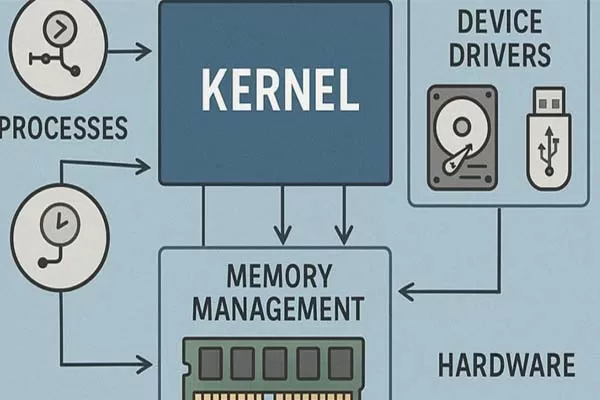
At their core, LLMs are advanced machine learning models trained on massive datasets of text—think books, articles, websites, and more. These models, often built using a transformer architecture, learn to understand and generate human-like language by identifying patterns, context, and relationships between words.
Key Steps in How LLMs Function:
- Training Phase:
- LLMs are fed vast amounts of text data.
- Using a process called "supervised" or "self-supervised" learning, they predict the next word in a sentence or fill in missing words, refining their understanding of grammar, syntax, and meaning over time.
- The transformer architecture, with its attention mechanism, allows the model to weigh the importance of different words in a sentence, capturing long-range dependencies and context.
- Tokenization:
- Text is broken down into smaller units called tokens (words or subwords).
- These tokens are converted into numerical representations (embeddings) that the model can process.
- Processing Input:
- When you give an LLM a prompt, it encodes the input tokens and uses its learned knowledge to interpret the context.
- The attention mechanism helps it focus on relevant parts of the input, even if the prompt is complex or lengthy.
- Generating Output:
- The model predicts the next token based on the input and its training.
- It repeats this process, building a response token by token, until it forms a coherent sentence or paragraph.
- Techniques like temperature sampling or top-k sampling fine-tune the creativity or precision of the output.
- Fine-Tuning:
- After initial training, LLMs can be fine-tuned on specific datasets (e.g., customer service logs or scientific papers) to specialize in certain tasks or domains.