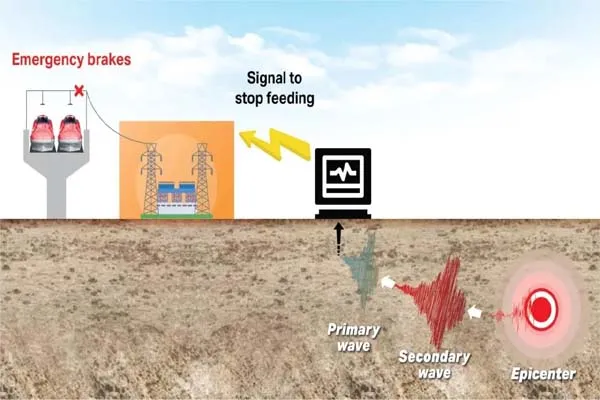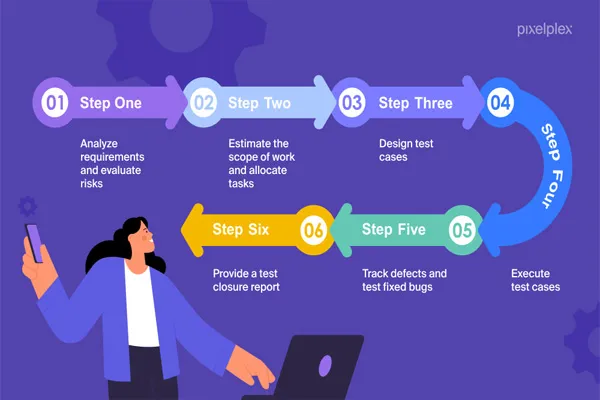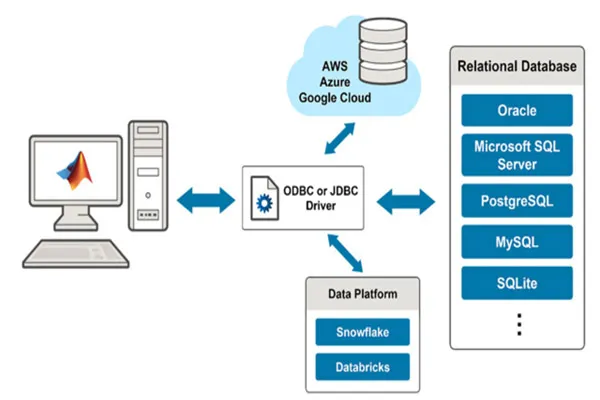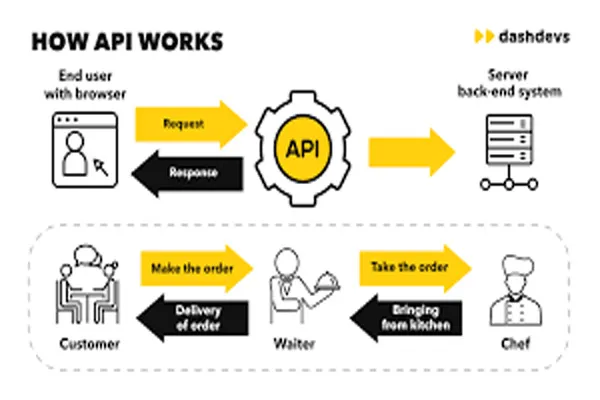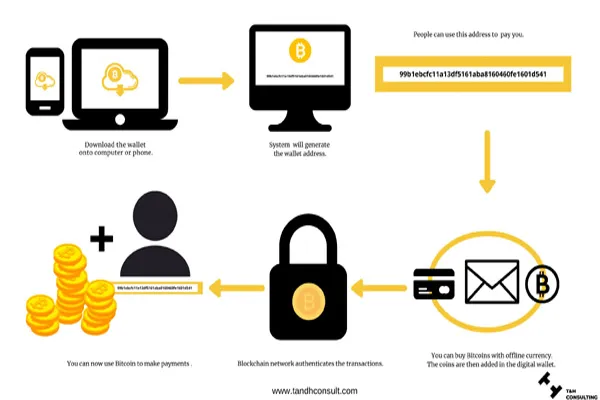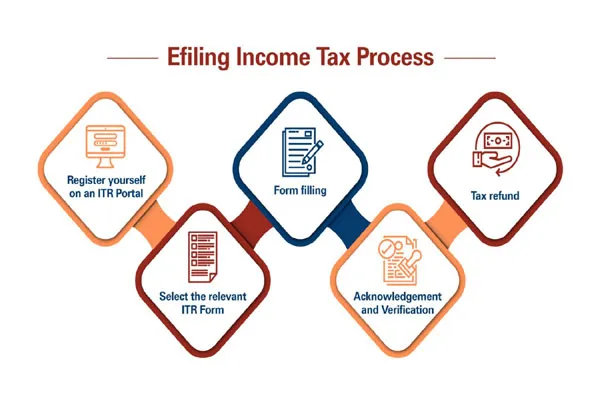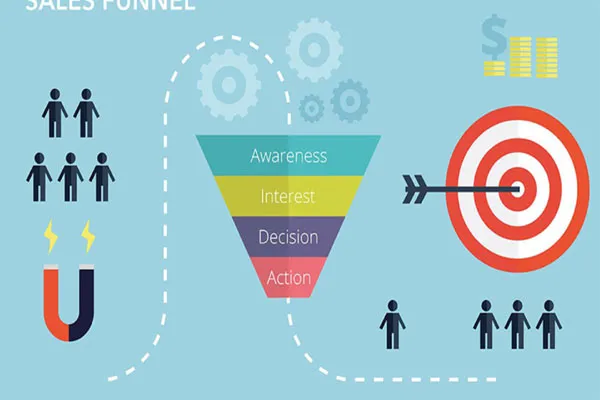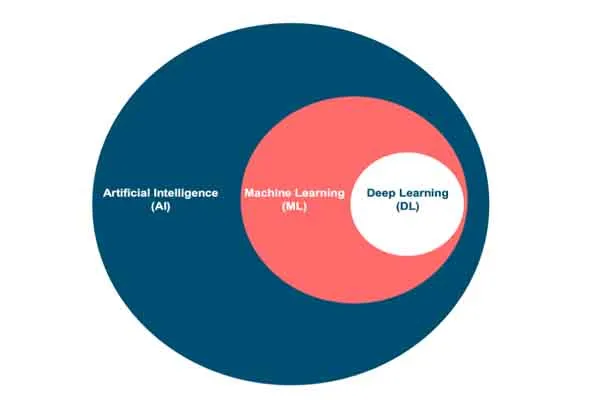
It seems like you’re asking about how large language models (LLMs) like me, Grok, are trained using content from the web. I’ll provide a general explanation of the process based on how these models are typically built.
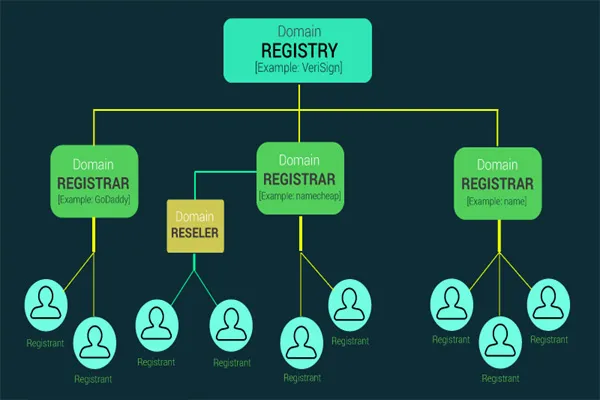
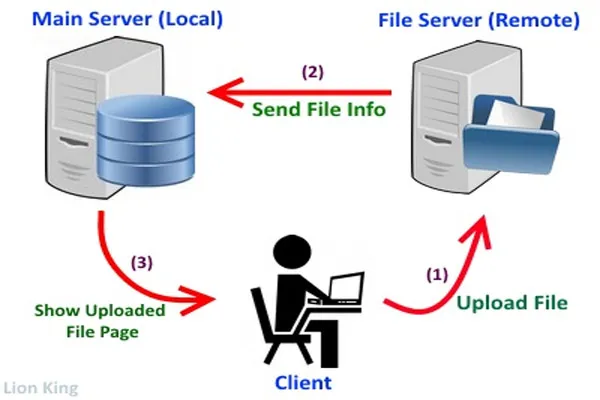
Large language models are trained on massive datasets that often include publicly available text from the internet—think websites, blogs, forums, and other openly accessible sources. The process starts with data collection, where organizations like xAI (my creators) use web crawlers to scrape text from a wide range of online locations. These crawlers systematically browse the web, gathering vast amounts of written content while respecting legal and ethical boundaries, like avoiding copyrighted material that’s restricted or behind paywalls (at least in theory!).
Once collected, this raw data—billions or even trillions of words—is cleaned and processed. That means removing junk like HTML code, ads, or gibberish, and sometimes filtering out low-quality or irrelevant content. The goal is to create a huge, diverse corpus of text that reflects how humans communicate across topics, styles, and languages.
From there, the model is trained using a technique called unsupervised learning. Essentially, the LLM is fed this text and learns to predict patterns—like what word or phrase might come next in a sentence—by adjusting its internal parameters over time. It’s not "copying" content in the traditional sense; it’s more like learning the rules of language and the structure of ideas from the data. For example, it might see thousands of articles about cats and figure out that "fluffy" often pairs with "kitten" without ever storing those exact sentences.
The web content isn’t the only source—books, public domain works, and other text archives might be mixed in—but the web’s scale and variety make it a goldmine for training. By the time training is done, the model doesn’t retain specific chunks of text verbatim. Instead, it’s distilled all that input into a complex web of probabilities and associations, which it uses to generate responses like this one.
If you meant something more specific—like how I, Grok, personally handle web content in real-time—feel free to clarify! I can search the web or X posts for you if you’d like, but my core knowledge is already baked in from that training process I just described.